知乎爬虫(一)展现了一个爬取并保存知乎回答下图片信息的完整过程,火影人物印象——B站弹幕词云分析 则简单展示了爬取文本数据,分析并可视化。这次我们更深入展示介绍用 csv模块 openpyxl模块 和 pandas模块 保存数据,和 pyecharts模块 强大的数据可视化功能。内容上,我们爬取豆瓣短评鞭尸2019年科幻巨制《上海堡垒》,微博部分参考:Python爬取2万条微博热搜,带你揭开热搜趋势!我添加了一些功能。
爬取数据
爬取豆瓣非常简单。《上海堡垒》短评网址:https://movie.douban.com/subject/26581837/comments?start=0&limit=20&sort=new_score&status=P,其中参数 start 表示这一页从第几条评论开始,limit 表示每一页有几条短评,所以我们对 start 参数使用 for 循环爬取前300条短评。
import requestsfrom bs4 import BeautifulSoup
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}for i in range(15): # 前300条短评 url = 'https://movie.douban.com/subject/26581837/comments?start=' + str(20 * i) + '&limit=20&sort=new_score&status=P' res = requests.get(url, headers=headers) res.encoding = 'utf-8' # 指定编码方式 if res.status_code == 200: print('爬取第' + str(1 + i) + '页') bs = BeautifulSoup(res.text, 'html.parser') info_list = bs.find_all('div', class_='comment-item') for info in info_list: UserName = info.find('div', class_='avatar').find('a')['title'] Votes = info.find('span', class_="votes").text Rating = info.find('div', class_='comment').find('h3').find( 'span', class_="comment-info").find( 'span', class_="rating")['title'] # 部分词匹配 Comment = info.find('span', class_="short").text
因为网页编码方式为 utf-8,所以用 res.encoding = 'utf-8' 指定。常用的编码表有 utf-8,gb2312,gbk等。
而爬取微博相对复杂一些。第一,日期。每日微博热搜的网址是:https://www.enlightent.cn/research/top/getWeiboHotSearchDayAggs.do?date=2019/10/20,其中参数 date 表示日期。所以在循环中,我们用 datetime模块 处理日期格式的数据。对输入的起始和最终日期,提取出中间所有的日期,格式均为:年/月/日。具体看代码:
import datetime
def get_between_day(begin_date, end_date): ''' 获得开始、结束日期之间,所有日期的字符串列表 :param begin_date 开始日期 :param end_date 结束日期 :return date_list ''' date_list = [] begin_date = datetime.datetime.strptime(begin_date, "%Y/%m/%d") # datetime.datetime.strptime,根据string, format 2个参数,返回一个对应的datetime对象 end_date = datetime.datetime.strptime(end_date, "%Y/%m/%d") while begin_date <= end_date: date_str = begin_date.strftime("%Y/%m/%d") # strftime() 函数接收以时间元组,并返回以可读字符串表示的当地时间,格式由参数format决定。 date_list.append(date_str) begin_date += datetime.timedelta(days=1) # datetime.timedelta类,用来计算二个datetime对象的差值的 return date_list
在评论中有大佬指出可以使用 pd.date_range(),这里试了试,强:
import pandas as pd
def get_between_day_improved(begin_date, end_date): ''' 上面函数的改进版 :param begin_date 开始日期 :param end_date 结束日期 :return date_list ''' date_list = [] between_date = pd.date_range(begin_date, end_date) # DatetimeIndex(['2019-10-01', '2019-10-02', '2019-10-03'], dtype='datetime64[ns]', freq='D') # <class 'pandas.core.indexes.datetimes.DatetimeIndex'> for date in between_date: date_str = date.strftime("%Y/%m/%d") # datetime 转 str: strftime() date_list.append(date_str)
获得字符串形式的日期后,即可循环提取数据。这里用 cookies 保持登陆。
def get_resou_data(begin_date, end_data): ''' 数据爬取 :return resou ''' header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win32; x32; rv:54.0) Gecko/20100101 Firefox/54.0', 'Connection': 'keep-alive' } cookies = {'v': '3; iuuid=1A6E888B4A4B29B16FBA1299108DBE9CDCB327A9713C232B36E4DB4FF222CF03; webp=true; ci=1%2C%E5%8C%97%E4%BA%AC; __guid=26581345.3954606544145667000.1530879049181.8303; _lxsdk_cuid=1646f808301c8-0a4e19f5421593-5d4e211f-100200-1646f808302c8; _lxsdk=1A6E888B4A4B29B16FBA1299108DBE9CDCB327A9713C232B36E4DB4FF222CF03; monitor_count=1; _lxsdk_s=16472ee89ec-de2-f91-ed0%7C%7C5; __mta=189118996.1530879050545.1530936763555.1530937843742.18'} resou = pd.DataFrame(columns=['date','title','searchCount','rank']) resou_date = get_between_day(begin_date, end_data) print('=====正在爬取对应日期的数据=====') for i in resou_date: print(i) url= 'https://www.enlightent.cn/research/top/getWeiboHotSearchDayAggs.do?date={}'.format(str(i)) html = requests.get(url=url, cookies=cookies, headers=header).content data = json.loads(html.decode('utf-8')) for j in range(100): resou = resou.append( {'date': i, 'title': data[j]['keyword'], 'searchCount': data[j]['searchCount'], 'rank': j+1}, ignore_index=True ) print('=====要求日期的数据爬取完成=====') return resou
保存数据
得到数据之后,我们需要保存数据。最简单的是保存为 txt 文件。有时可能遇到有些表情包无法编译导致出错,我们忽略 utf-8 无法识别的部分,实际效果为跳过。
with open('豆瓣上海堡垒短评.txt',"a+") as file: string = UserName+' '+Rating+' '+Comment+' '+Votes+'\n====================================\n' file.write(string.encode('utf-8','ignore').decode('utf-8'))
但保存为 text 的数据仅仅是字符串,没有结构,更好的一个选择是保存为 csv 文件。引入 csv 模块,用追加模式打开一个 csv 文件,指定为 file,用 csv.writer(file) 创建一个写入对象,最后用 writer.writerow(list) 一次写入一行信息,或者 writer.writerows(list of lists) 同时写入多行信息。写好的文件可以用 excel 查看。
import csv
with open('豆瓣上海堡垒短评.csv', "a+", newline='',encoding='utf-8') as file: writer = csv.writer(file) writer.writerow([UserName, Rating, Comment, Votes])
最后介绍如何保存为 xlsx 文件。首先介绍 excel 的两个基本概念。
1、工作簿 workbook。
2、活动表 sheet。
在 Python 中,我们先引入 openpyxl模块,然后创建工作簿 wb,在工作簿中获取一个工作表 sheet,赋予表格内容,最后保存工作簿。其中,给表格赋值,既可以直接给单元格赋值,也可以先定义列表,然后直接给一行赋值。
import openpyxl
wb = openpyxl.Workbook() # 创建工作薄
sheet = wb.active # 获取工作薄的活动表sheet.title = "ShortComment" # 工作表重命名
sheet['A1'] = 'UserName' #加表头,给单元格赋值sheet['B1'] = 'Rating'sheet['C1'] = 'Comment'sheet['D1'] = 'Votes'
sheet.append([UserName, Rating, Comment, Votes])
wb.save('豆瓣上海堡垒短评.xlsx') # 保存结果如上图所示。
但现在其实不用这么麻烦,只要将数据转化为 DataFrame 类,直接用 .to_csv() 和 .to_excel() 即可。同样的,读取数据,直接用 .read_csv() 和 .read_excel() 即可。总之,强烈推荐 pandas 模块,调用和保存数据方便,数据为 DataFrame 格式,具有良好的结构。
import pandas as pd
df.to_excel(excel_path, sheet_name='short_comments')df = pd.read_excel(excel_path)
数据分析与可视化
jieba模块 见 火影人物印象——B站弹幕词云分析,这次详细写 pyecharts模块 的用法。最强参考当然是作者所写简介 https://pyecharts.org/#/zh-cn/intro。
1、词云
可以像上次一样,用 jieba 分析好,让 WordCloud 绘制。其中:
第 9 行,设置 pyecharts 内置的风格,宽高,如 init_opts=opts.InitOpts(width='1800px',height='1500px')。
第 10 行,word_size_range 设置词大小的范围。设置形状可以用 shape=SymbolType.RECT (ROUND_RECT,TRIANGLE,DIAMOND,ARROW,只有这些),或直接写 shape='circle', 'cardioid', 'diamond', 'triangleforward', 'triangle', 'pentagon', 'star'。
import jieba.analysefrom pyecharts import options as optsfrom pyecharts.globals import SymbolType, ThemeTypefrom pyecharts.charts import WordCloud
title_string = ' '.join(resou['title'])keywords_count_list_TR = jieba.analyse.textrank(title_string, topK=50, withWeight=True)word_cloud_TR = ( WordCloud(init_opts=opts.InitOpts(theme=ThemeType.PURPLE_PASSION)) .add("", keywords_count_list_TR, word_size_range=[20, 50], shape=SymbolType.RECT) .set_global_opts(title_opts=opts.TitleOpts(title="微博热搜词云TOP50", subtitle="基于TextRank算法的关键词抽取")) .render('Weibo_WordCloud_TR.html') )
考虑到标题已经被高度提炼,我们可以不用 jieba,而是用“热搜指数”这个数据来绘制词云:
data = [(resou['title'][i], resou['searchCount'][i]/1000000) for i in range(word_title.shape[0])] # 如 [('title1', float1), ('title2', float2), ...]

如果想要匹配主题,就加上模糊匹配:
def fuzzy_match_title(resou, key_word): ''' 匹配词的热搜标题统计 :param resou :param key_word 若是多个关键词,格式 key_word1|key_word2|key_word3 :return word_title ''' # 预处理热评 resou['searchCount'] = resou['searchCount'].apply(int) # .str.contains()模糊匹配 word_title = resou[resou['title'].str.contains(key_word)] # DataFrame类 # 预处理数据 若热搜重复,取热度高的 word_title = word_title.groupby(['title'],as_index=False).agg({'searchCount':['max']}) # 重命名列名 word_title.columns = ['title', 'count'] # DataFrame类 return word_title def fuzzy_match_title_cloud(resou, key_word): ''' 标题云 :param resou :param key_word ''' # 预处理标题 words = re.split("\|", key_word) word = 'or'.join(words) # 标题不能出现 | word_title = fuzzy_match_title(resou, key_word) data = [(word_title['title'][i], word_title['count'][i]/1000000) for i in range(word_title.shape[0])] # word_title.shape[0]行数 # list类 形如 [('title1', float1), ('title2', float2), ...] /1000000 必须 wc = ( WordCloud(init_opts=opts.InitOpts(theme=ThemeType.ROMA)) .add("", data, word_size_range=[20, 50], shape='pentagon') .set_global_opts(title_opts=opts.TitleOpts(title='关于{}的热搜标题云.html'.format(word), subtitle='基于searchCount')) .render('关于“{}”的热搜标题云.html'.format(word)) ) print('=====关于“{}”的热搜标题云完成====='.format(word))

2、柱状图
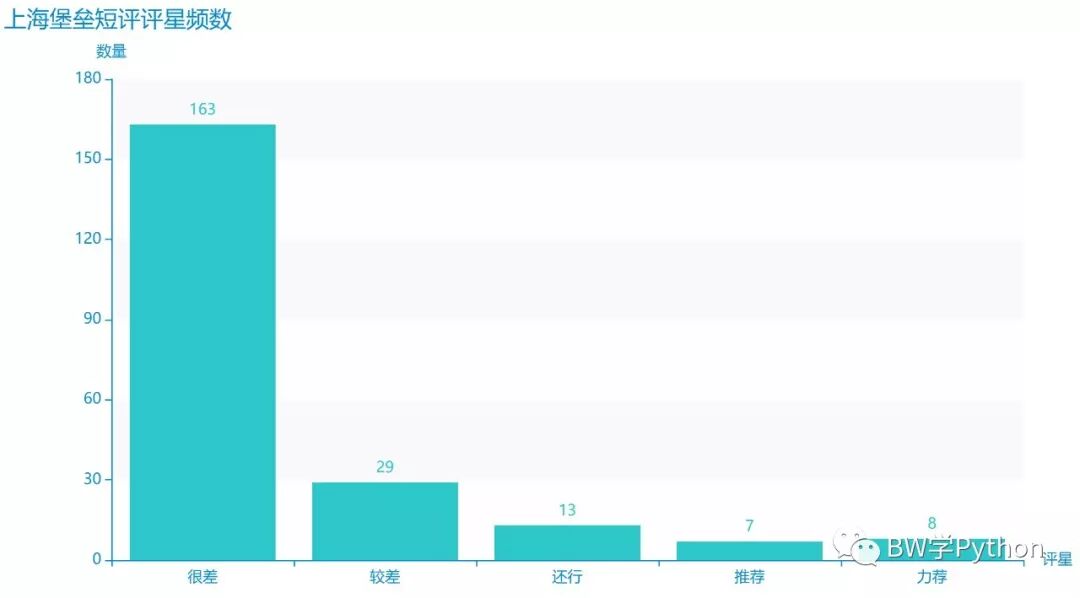
我们先统计上海堡垒的评分,并绘制柱状图。
第3、4行,数据以列表的格式分别输入 x 轴和 y 轴。
第5行,xy轴互换。
第6行,调整显示数据相对于柱的位置。
第9、10行,设置轴标名称。第11行展示如何将字体倾斜。
第14行,保存。
# 标记为注释的部分可以解决 x 轴标签因字放不下而显示不全的问题。
rating_bar = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) .add_xaxis(['很差', '较差', '还行', '推荐', '力荐']) .add_yaxis("", rating) # .reversal_axis() # .set_series_opts(label_opts=opts.LabelOpts(position="right")) .set_global_opts( title_opts=opts.TitleOpts(title="上海堡垒短评评星频数"), yaxis_opts=opts.AxisOpts(name="数量"), xaxis_opts=opts.AxisOpts(name="评星") # xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)), ) )rating_bar.render('comment-rating-bar.html')
3、饼图,玫瑰图
输入数据的格式同词云。
第5行,设置显示标签的格式。
第12行,设置玫瑰图内外半径,可用数字或百分比。
第13行,设置玫瑰图圆心坐标,可用数字或百分比。
第14,28行,设置玫瑰图是以半径,还是面积(等半径)来体现数值差异。
第17行,设置图例位置等细节。
rating_pie = ( Pie(init_opts=opts.InitOpts(theme=ThemeType.WALDEN)) .add("", [list(z) for z in zip(['很差', '较差', '还行', '推荐', '力荐'], rating)]) .set_global_opts(title_opts=opts.TitleOpts(title="上海堡垒短评评星频数")) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) .render('comment-rating-pie.html'))rating_pie = ( Pie() .add("", [list(z) for z in zip(['很差', '较差', '还行', '推荐', '力荐'], rating)], radius=["30%", "75%"], center=["40%", "50%"], rosetype="radius") .set_global_opts( title_opts=opts.TitleOpts(title="上海堡垒短评评星频数"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical") ) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) .render('comment-rating-pie玫瑰图R.html'.format(word)) )rating_pie = ( Pie() .add("", [list(z) for z in zip(['很差', '较差', '还行', '推荐', '力荐'], rating)], radius=["30%", "75%"], center=["40%", "50%"], rosetype="area") .set_global_opts( title_opts=opts.TitleOpts(title="上海堡垒短评评星频数"), legend_opts=opts.LegendOpts(type_="scroll", pos_left="90%", orient="vertical") ) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) .render('comment-rating-pie玫瑰图A.html'.format(word)) )


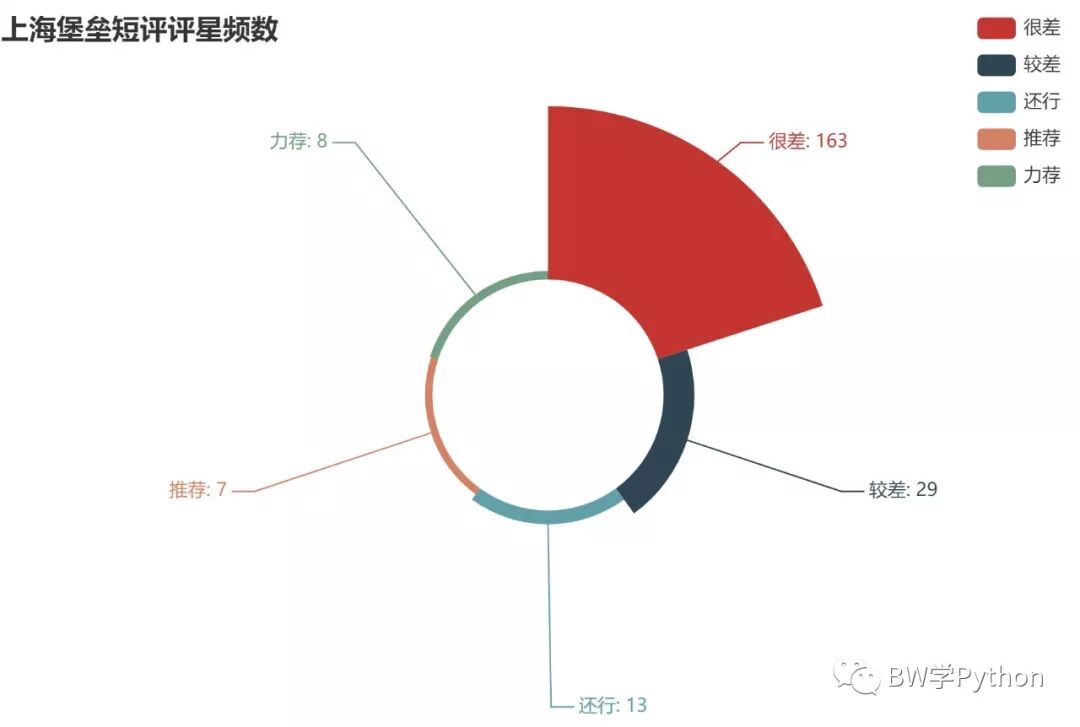
真是烂啊!
4、日历图
第6行体现了 DataFrame 类数据的便利之处:按日期聚合求均值。
第9-12行,数据格式是:[[date1, count1], [date2, count2], ...]。
第15行,输入数据,和日历起止时间。
第18-26行,设置图例。
def draw_calendar(resou, begin_date, end_data): ''' 绘制日历图 :param resou ''' resou['searchCount'] = resou['searchCount'].apply(int) # 爬取的热度为字符串,转化为整数 resou_dt = resou.groupby('date', as_index=False).agg({'searchCount':['mean']}) # 按日期分组,再聚合得到每日热搜数量均值 resou_dt.columns = ['date','avg_count'] data = [ [resou_dt['date'][i], resou_dt['avg_count'][i]] for i in range(resou_dt.shape[0]) ] calendar = ( Calendar(init_opts=opts.InitOpts(width='1800px',height='1500px')) .add("", data, calendar_opts=opts.CalendarOpts(range_=[begin_date, end_data])) .set_global_opts( title_opts=opts.TitleOpts(title="2019每日热搜平均指数",pos_left='15%'), visualmap_opts=opts.VisualMapOpts( max_=3600000, min_=0, orient="horizontal", is_piecewise=False, pos_top="230px", pos_left="100px", pos_right="10px" ) ) .render('日期热力图.html') )

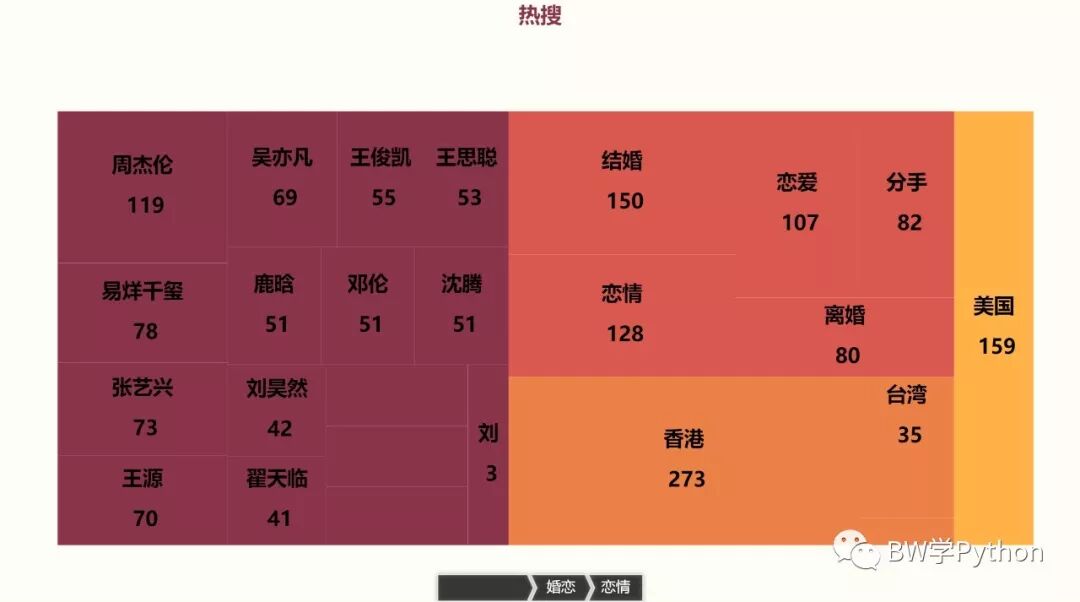
5、矩形树图
矩形树图的数据格式的要求很特别,必须是:最外层是列表,其中每个矩形是字典,字典含三个元素:"value", "name","children"(非必须)。其中 children 又嵌套一个矩形。
这里我们可以通过提前定义好父子关系还绘制矩形树图:
def tree_map(resou, total_lst): ''' 矩形树图 这里设置为最多两层 ''' t_m_lst = [] for pair in total_lst: m = 0 w_n_lst = [] if pair[1] == []: m = fuzzy_match_title(resou, pair[0]).shape[0] t_m_lst.append({'value': m, 'name': pair[0]}) else: for word in pair[1]: n = fuzzy_match_title(resou, word).shape[0] w_n_lst.append({'value': n, 'name': word}) m += n t_m_lst.append({'value': m, 'name': pair[0], 'children': w_n_lst}) tree = ( TreeMap(init_opts=opts.InitOpts(theme=ThemeType.ESSOS)) .add("", t_m_lst, pos_left=0, pos_right=0, pos_top=50, pos_bottom=50) .set_global_opts(title_opts=opts.TitleOpts(title="热搜",pos_left='center')) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}\n\n {c}",font_size=17, # 名字\n\n数据 大小17 color='black',position='inside',font_weight='bolder')) # 黑色,位置在内部,粗体 .render('矩形树图.html') ) print('=====矩形树图完成=====')
if __name__ == '__main__': total_lst = [ ( '明星', ["周杰伦", "张艺兴", "易烊千玺", "杨超越", "吴亦凡", "王思聪", "沈腾", "翟天临", "迪丽热巴", "邓伦", "蔡徐坤", "刘昊然", "王俊凯", "王源", "鹿晗", "刘强东"] ), ( '婚恋', ["离婚", "结婚", "分手", "恋爱", "恋情"] ), ( '中国', ["内地", "台湾", "香港", "澳门"] ), ( '美国', [] ) ] # 示例 tree_map(resou_WL, total_lst)
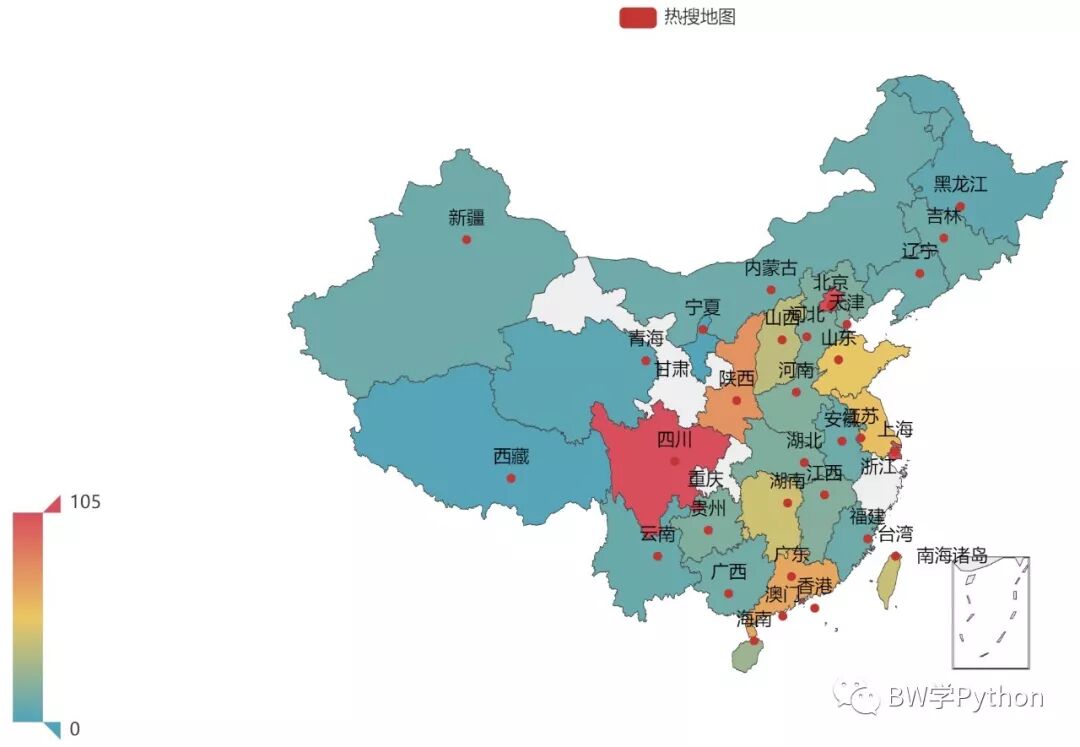
6、热力图
如果数据和地理信息有关,我们可以用 map() 和 geo() 绘制热力图。所以我们统计各地名上热搜的数据。
数据格式:[('地名1':数据1), ('地名2':数据2), ...]。
第22,33行,输入地图类型。也可以是世界,各省,市。
第22,33行,设置地图可以显示的最大最小值,可以不是实际数据的最大最小值。
第27行,热力图形式,scatter, effectScatter, heatmap。
def draw_heatmap(resou): province_captal_name = [ '北京|京', '天津|津', '上海|沪', '重庆|渝' '浙江|浙|杭州', '安徽|皖|合肥', '福建|闽|福州', '香港', '澳门', '台湾|台北', '江西|赣|南昌','山东|鲁|济南', '河南|豫|郑州', '内蒙古|内蒙|呼和浩特', '湖北|鄂|武汉', '新疆|乌鲁木齐', '湖南|湘|长沙', '宁夏|银川', '广东|粤|广州','西藏|拉萨','海南|琼|海口','广西|桂|南宁','四川|川|蜀|成都','河北|冀|石家庄','贵州|黔|贵阳', '山西|晋|太原','云南|滇|昆明','辽宁|辽|沈阳','陕西|陕|秦|西安','吉林|长春', '甘肃|陇|兰州','黑龙江|哈尔滨','青海|西宁', '江苏|南京' ] province_lst = [ '北京', '天津', '上海', '重庆' '浙江', '安徽', '福建', '香港', '澳门', '台湾', '江西','山东', '河南', '内蒙古', '湖北', '新疆', '湖南', '宁夏', '广东','西藏','海南','广西','四川','河北','贵州','山西','云南','辽宁','陕西','吉林', '甘肃|', '黑龙江','青海', '江苏' ] province_distribution = [] for province, word in zip(province_lst, province_captal_name): province_distribution.append( (province, fuzzy_match_title(resou, word).shape[0]) ) resou_geo = ( Geo() .add_schema(maptype="china") .add("热搜HEATMAP", province_distribution, type_=GeoType.HEATMAP) # Geo 图类型,有 scatter, effectScatter, heatmap .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( visualmap_opts=opts.VisualMapOpts(min_=0, max_=105), title_opts=opts.TitleOpts(title="HEATMAP"), ) .render(path="热搜HEATMAP.html") ) resou_map = ( Map() .add("热搜地图", province_distribution, "china") .set_global_opts( visualmap_opts=opts.VisualMapOpts(min_=0, max_=105), ) .render(path="热搜地图.html") )
我们可以看到,最常上热搜的地名在京津,香港,沪浙,四川,陕西等地。


源码地址:
知乎:https://github.com/BWfight/zhihu_spider
豆瓣:https://github.com/BWfight/douban_spider
微博:https://github.com/BWfight/weibo_spider


